前言
Lua 开发者通常听说或使用过 LuaJIT,但是可能因为种种原因未能理解其工作原理,在这里分享一篇 Jakob Erlandsson 和 Simon Kärrman 的硕士毕业论文,TigerShrimp: An Understandable Tracing JIT Compiler,该论文讲述了如何为 JVM 开发一个 Tracing JIT,并附带了源码以及可视化工具。下文将简要剖析一些其实现原理。
编译流程
TigerShrimp 基于 JVM Bytecode,使用 Javac 将 Java 代码文件编译为 .class 文件,后直接进行 decode .class 文件,通过这种方式绕过 Parser 阶段,得到 bytecode。
执行流程
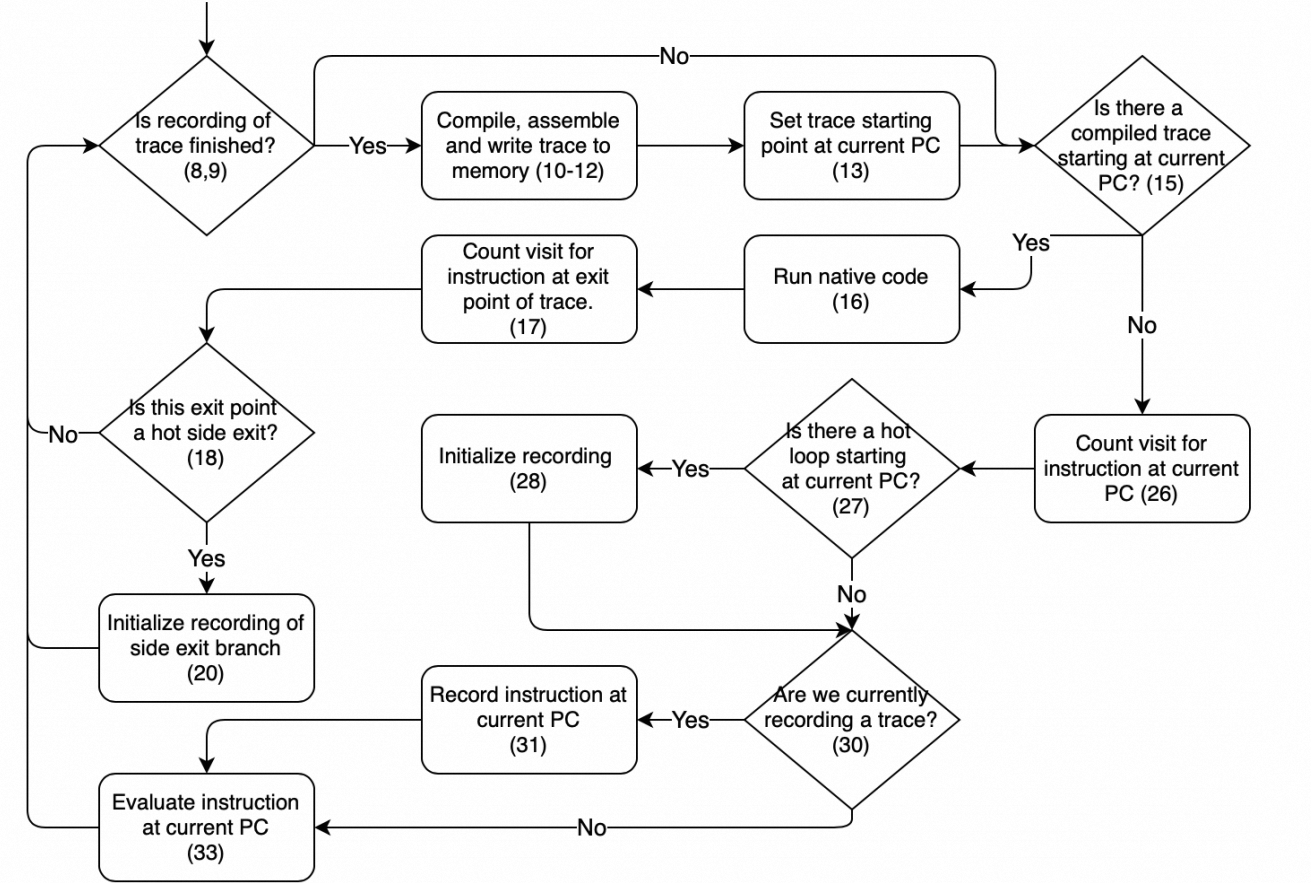
TigerShrimp 内部有个简单的 Interpreter,用以直接执行 bytecode,执行每一条 Instruction时,会记录当前的 pc (二元组,记录函数索引和指令索引,不然指令索引可能重复),是否为热路径,若为热路径,则会执行 record 流程,记录每一条执行的指令。(通常记录循环,循环有回边,记录执行次数,执行次数大于一阈值,则认为是热路径)。
若已经有 native code,即已经是热路径并完成了生成机器码的工作,则直接执行 native code。
记录流程
常规操作,记录每一条 Instruction,只有在分支语句时需要特殊处理。因为这里是 record 的过程中,是顺序执行的,所以一定不会有分支,相当于这些 Instruction 组成了一个 BasicBlock,但是原始的指令是有分支的,需要将分支进行翻转处理。具体例子如下:
1 | 1: if (a < b): |
若 a > b 则会执行到 y() 即 pc = 4 的位置,若原样记录 a < b 这条指令,逻辑就错了,因此需要翻转指令为 a >= b 。
指令记录到 return 时或回到循环开始的位置,则该条热路径记录完成。
记录编译
热路径记录完成后,需要进行编译为机器代码,TigerShrimp 选择了 asmjit 库来帮助生成机器代码。具体的字节码翻译过程此处略过,只分析函数进入的准备工作,以及分支判断失败时的处理(如何正确的回退到解释器)。
Prologue
1 | initCode.push_back( |
ExitInformation 用于描述当前执行的堆栈信息,使用数组来模拟堆栈,以便在执行 native code 过程中,因为分支判断失败跳回 Interpreter 时恢复当前的堆栈信息,继续解释执行。
traces 用于存储所有跳出点的 native code 地址,用于实现 Trace Stitching,简单的说就是当分支判断失败后,不要直接回到解释器,而是先看看这个退出点是否存在另一条热路径,若有则直接转移控制权。
Bailout
若分支判断失败,将会直接跳转到 bailoutcode 的位置,此时 RSI 寄存器已经存储了当前的 pc 值,便于之后恢复到寄存器执行。
1 | void Compiler::compileBailoutFor(Op label) { |
由于执行执行过程中不会使用到物理栈,都是通过 ExitInfomation->variables 数组来模拟,所以此时的 RAX 为 handleTraceExit , RDI 为 ExitInformation ,跳入 _handleTraceExit
1 | bailoutCode.push_back({x86::LABEL, exitLabel}); |
1 | asm("_handleTraceExit:;" |
查找当前退出 pc 是否有一条热路径,若有则直接跳入继续执行,没有就将退出 pc 返回回去。
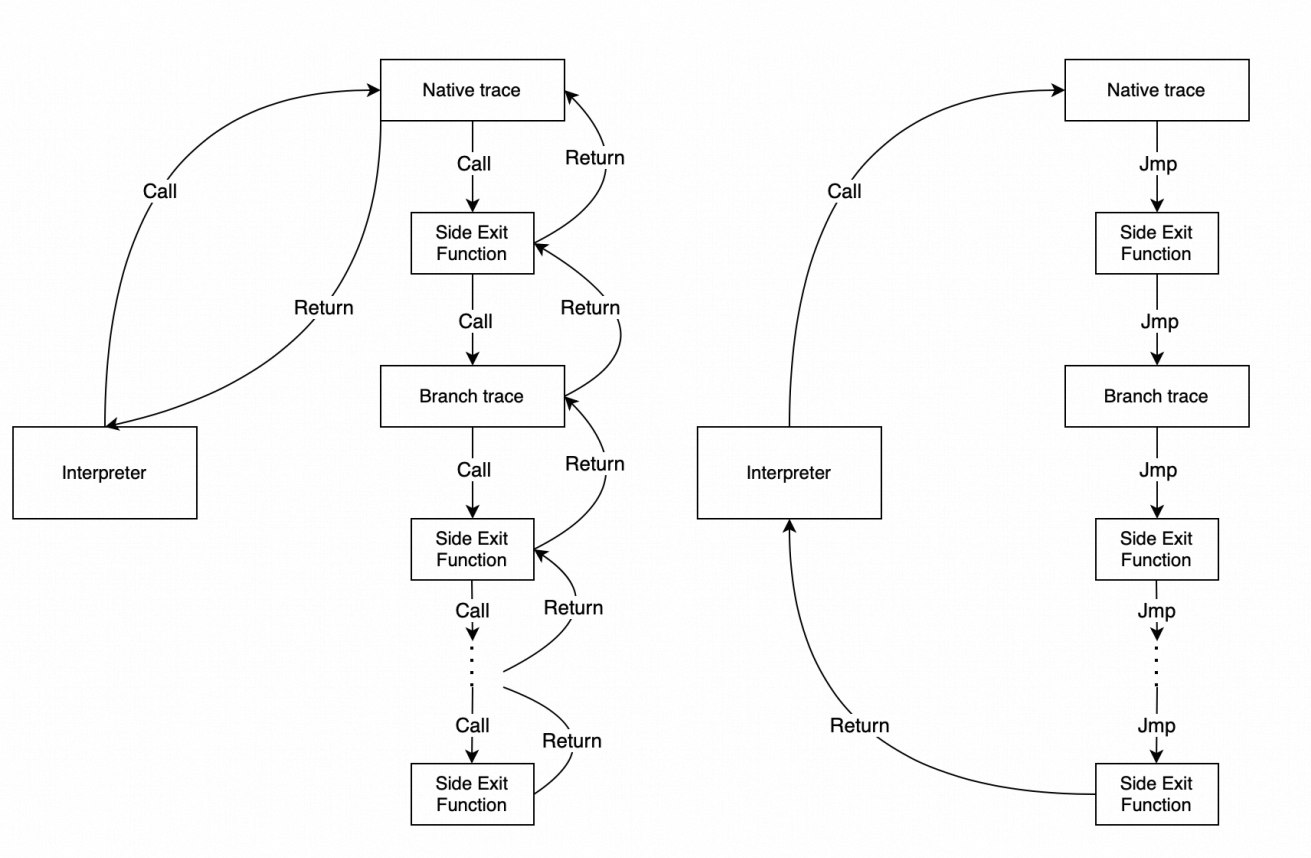
使用 JMP 尾调用,避免多次函数调用的性能损耗。
总结
TigerShrimp 为了实现简单,选择直接从 bytecode 解释执行,跳过繁杂的 Parser 生成 AST 阶段,其次为了实现栈上替换(OSR),直接不使用物理栈,使用数组模拟,方便回退到解释器,易于理解。