Lab 3 练习补充
在练习开始之前 先讲讲 两个数据结构
1 | struct mm_struct { // 描述一个进程的虚拟地址空间 每个进程的 pcb 中 会有一个指针指向本结构体 |
总而言之就是 mm_struct 描述了整个进程的虚拟地址空间 而 vma_struct 描述了 进程中的一小部分虚拟内存空间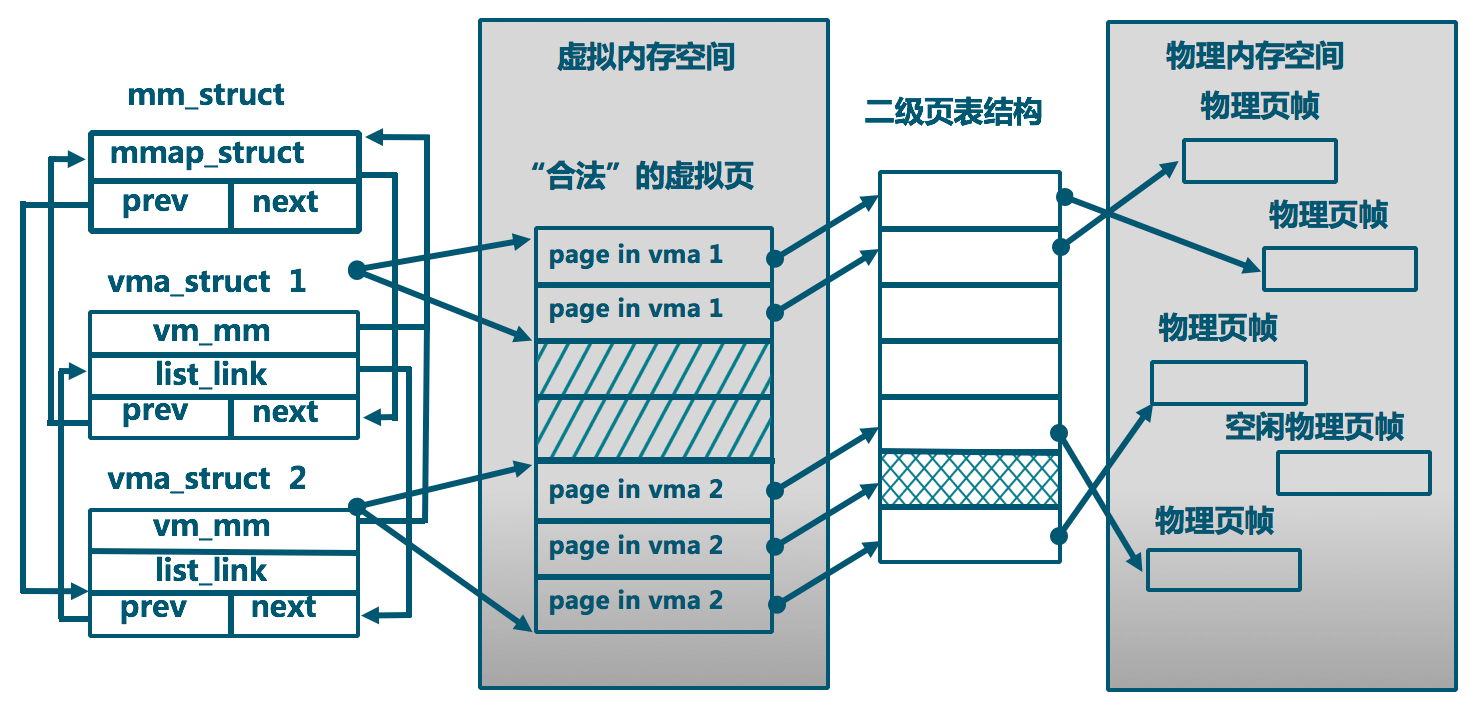
练习0:填写已有实验
本实验依赖实验1/2。请把你做的实验1/2的代码填入本实验中代码中有“LAB1”,“LAB2”的注释相应部分。
1 | 就下面三个 复制过去就好 |
练习1:给未被映射的地址映射上物理页
完成do_pgfault(mm/vmm.c)函数,给未被映射的地址映射上物理页。设置访问权限 的时候需要参考页面所在 VMA 的权限,同时需要注意映射物理页时需要操作内存控制 结构所指定的页表,而不是内核的页表。注意:在LAB3 EXERCISE 1处填写代码。执行
1 | make qemu |
后,如果通过check_pgfault函数的测试后,会有“check_pgfault() succeeded!”的输出,表示练习1基本正确。
1 | do_pgfault() |
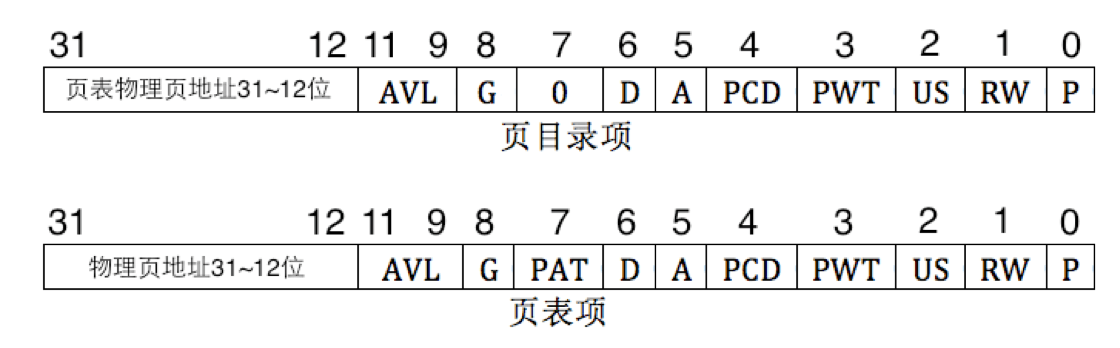
- 请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中组成部分对ucore实现页替换算法的潜在用处。
1 | 其实很想说这道题之前不是问过了吗?... |
- AVL CPU 不理会这个属性 可以不管 (有可能在32位系统使用大过 4G内存的时候 用到这几位)
- G Global 全局位 表示是否将虚拟地址与物理地址的转换结果缓存到 TLB 中
- D Dirty 脏页位 当 CPU 对这个页进行写操作时 会置 1
- PAT Page Attribute Table 页属性表位 置 0
- A Accessed 访问位 若为 1 则 说明 CPU 访问过了 CPU 会定时清 0 记录被置 1 的频率 当内存不足时 会将 使用频率较低的页面换出到外存 同时将 P位 置 0 下次访问 该页时 会引起 Pagefault 异常 中断处理程序再将此页换上
- PCD Page-level Cache Disable 页级高速缓存位 置 0 即可 读的时候 高速缓存是否有效 若有效则直接从高速缓存中读出 若无效的话 则必须实实在在的从 I/O 端口去读数据
- PWT Page-level Write-Through 页级通写位 控制是先写到高速缓存里再慢慢回写到内存里 还是 直接慢慢写到内存里
- US User/Superviosr 普通用户/超级用户位
- RW Read/Write 读写位
- P Present 存在位 (虚拟页式存储的关键位 若为 0 则发起缺页异常)
- 如果ucore的缺页服务例程在执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
1 | 页访问异常 会将产生页访问异常的线性地址存入 cr2 寄存器中 并且给出 错误码 error_code 说明是页访问异常的具体原因 |
练习2:补充完成基于FIFO的页面替换算法
完成vmm.c中的do_pgfault函数,并且在实现FIFO算法的swap_fifo.c中完成map_swappable和swap_out_victim函数。通过对swap的测试。注意:在LAB3 EXERCISE 2处填写代码。执行
1 | make qemu |
后,如果通过check_swap函数的测试后,会有“check_swap() succeeded!”的输出,表示练习2基本正确。
请在实验报告中简要说明你的设计实现过程。
1 | 此时完成的是 FIFO 置换算法 因此 每次换出的都应该是 最先进来的 页 |
请在实验报告中回答如下问题:
- 如果要在ucore上实现”extended clock页替换算法”请给你的设计方案,现有的swap_manager框架是否足以支持在ucore中实现此算法?如果是,请给你的设计方案。如果不是,请给出你的新的扩展和基此扩展的设计方案。并需要回答如下问题
- 需要被换出的页的特征是什么?
- 在ucore中如何判断具有这样特征的页?
- 何时进行换入和换出操作?
1 | 当然能够支持 |
至此 这两道题就完成了 比之前的 Lab 要简单多了 这次只花了 一天半时间 下面是 Challenge 花了我一个小时(跑出去饭堂吃饭 哈哈哈哈哈 0.0)
扩展练习 Challenge 1:实现识别dirty bit的 extended clock页替换算法
1 | swap_fifo.c |
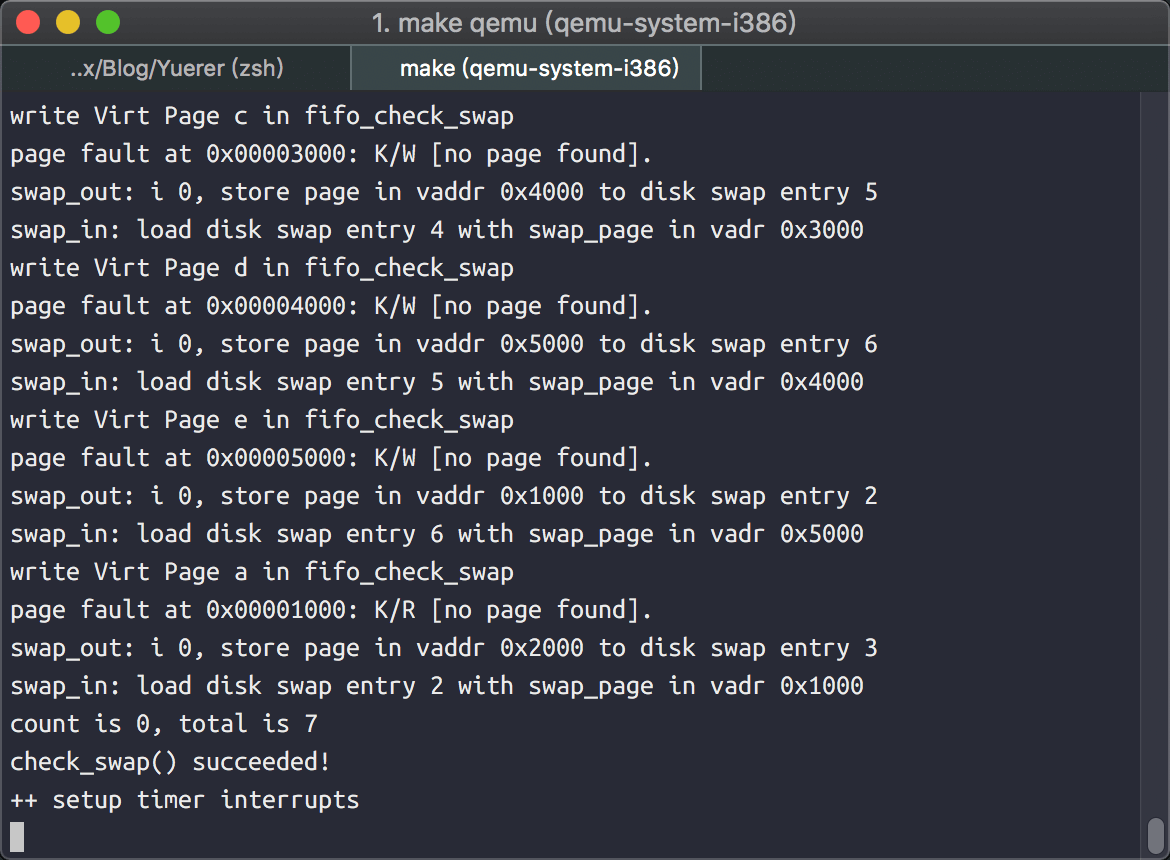
最后放上 运行结果