在上一篇关于 Python3 源码剖析中,剖析 float 的实现主要是阅读的 Python 3.10 的源码,但是在我看到 PEP-659 这篇关于指令特化(Specializing Adaptive Interpreter)的提案时,我就被它吸引了,因为这就是我之前想给 Lua 提速加的功能之一,冲着对它的热情,我决定将阅读的 CPython 版本提升到 3.11 ,这一篇就来剖析一下指令特化的实现,我们将通过两个对象做加法进行分析。
对象相加
首先通过 Python 自带的 dis 工具进行分析,分析两个对象相加的流程。
1 | from dis import * |
可以看到两个对象相乘的指令码为 BINARY_OP ,我们跟踪到 CPython 中,可以确定会调用到 PyNumber_Add 函数中。
1 | static const binaryfunc binary_ops[] = { |
PyNumber_Add 实现也很简单,先看看这两个对象支不支持该二元运算符,不支持,则看看支不支持 concat 操作。
1 | PyObject * |
binary_op1 则是分别对左右两个对象进行判定,查看是否支持相加的操作。
1 | static PyObject * |
可以看出一个小小的二元运算,需要经历以下几个过程。
- 确定二元运算的类型(加法)。
- 确定两个对象的类型,查看两个对象是否支持加法。
- 确定是否支持
concat。
如果有一个办法可以提前知道这两个对象的类型,提前确定它们的二元运算是什么就好了,这样就可以绕过一系列的条件判断语句,直达核心,省去大量的预测分支,从而提高性能。
指令特化
思路
经过前面的背景铺垫,我们可以先试想一下,如何去做指令特化?
首先要明确地是什么时候做指令特化?如果每个函数执行的时候都做一次指令特化,那么很可能会消耗更多的时间,这点和 JIT 的思路一致,只有对调用频率高的函数做优化才有意义。
其次要明确指令特化失败了怎么办?因为 Python 是脚本语言,很可能下次传进来的对象不再是原来的那个类型了,这个时候就可能会发生指令特化失效的情况,但是如果每次都在指令特化后的执行流程中检查对象的类型,那又回到了老路子,性能可能提升不了,解决这个问题的思路是,在指令后面缓存一些数据,减少条件判断的个数。
实战
接下来我们将开始实战指令特化,首先根据前面分析,我们需要记录每个对象的执行次数,还记得前面的字节码吗?RESUME 就是拿来做这个事情的。
在编译生成字节码阶段,每当进入一个新的作用域时,就会创建一个 RESUME 的指令,这是新版本中特有的。
1 | static int |
可以看出,co_warmup 会在每次进入该作用域时自增,当其为 0 时,进行 quicken 操作。其默认值目前为 -8 。
1 |
|
那么 quicken 操作是什么呢?其实就是将原本的指令替换为 自适应 指令,自适应指令也会有个变量记录进入该指令的次数,当达到一定次数时,才考虑将其进行特化。之所以不在一开始就生成 自适应的二元操作指令,主要是避免一些性能损耗吧,毕竟有一些函数调用次数少。
1 | uint8_t _PyOpcode_Adaptive[256] = { |
在此处 BINARY_OP 的自适应指令则为 BINARY_OP_ADAPTIVE ,同时细心的读者可以发现,在 quicken 过程中,还会将 RESUME 替换为 RESUME_QUICK 这主要是因为,既然都已经决定特化了这个函数了,我再每次都去算进入这个函数多少次,意义不大,想办法将其特化掉,省去一部分性能损耗。
BINARY_OP_ADAPTIVE 在这条指令后面藏了一个缓存,存储了当前指令还差多少次进行特化(我猜测是因为与0对比的时候,运算的比较快),当 counter 为0时,进行特化。
目前默认的 counter 为 53,作者说:大了优化的少,小了整天优化,只有50附近比较靠谱,但是又不想选50,就选了个53质数。
当回退的时候,指令特化失败时,会被修改为 64 。
1 | TARGET(BINARY_OP_ADAPTIVE) { |
_Py_Specialize_BinaryOp 的过程也非常简单,就是检查对象类型,还有操作类型,进行决策即可。
1 | void |
关键是如果一开始指令特化成功,后面传入的对象不再是原来的对象了,那应该怎么回退呢?带着这个问题,我们来到特化后的指令 BINARY_OP_ADD_FLOAT 。
可以看到,在这里就只是简单检查一下两边对象类型,然后快速的用浮点相加完成了两对象相加,这就是性能提速的原因。
DEOPT_IF 就是用来判断是否特化失效的宏,特化失败走向 miss 。
1 |
|
当指令特化失效后,就会找回该特化指令原始的指令进行执行,还会尝试去再次特化该指令。
1 | miss: |
整个指令的变化可以参考下图。
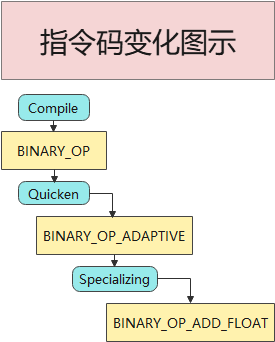
至此我们的分析结束,指令特化真好玩,下次(一定)我就将它实现到 Lua 上。