一直觉得关系型数据库非常难用,在使用之前要先定好表的结构,中途修改存储结构,改动就会非常繁杂,特别是 外键 这玩意离开了学校就再也没见过。好在在 游戏领域 中,用的最多的都是 NoSQL 。
熟悉我风格的人,可以看出这个系列的标题,不再是 源码剖析,而是只有 剖析 两字,主要是考虑到 Redis 6.0 的代码量已经挺大了,同时网络中又有大量关于 Redis 数据结构的源码剖析,没必要再炒冷饭了。
出于以上的原因,我将 Redis 分为几个部分进行剖析和讨论。
- 异步机制
- 主从同步
- 集群
- 数据结构
本篇主要是来剖析 Redis 为了避免 阻塞 ,是如何运用 多进程 与 多线程,这两种异步机制的。
阻塞点
Redis 一般有以下几种阻塞的点。
从网络交互来看有
- 网络 I/O (多线程)
- 客户端交互 (部分删除用多线程
BIO) - 传输 RDB 快照 (多进程)
从磁盘交互又分
- 关闭文件 (多线程
BIO) - 记录 AOF 日志 (多线程
BIO) - AOF 日志重写 (多进程)
- RDB 快照生成 (多进程)
网络 I/O (多线程)
Redis 在早期的版本中 采用的是 单线程 + I/O 多路复用 的模型,而在最新的 6.0 ,采用了 Thread I/O ,默认不会开启,开启需要在配置中加入以下两行。
1 | io-threads-do-reads true // 开启多线程读和解析执行 |
Redis 在初始化的时候,会调用 initThreadedIO 。
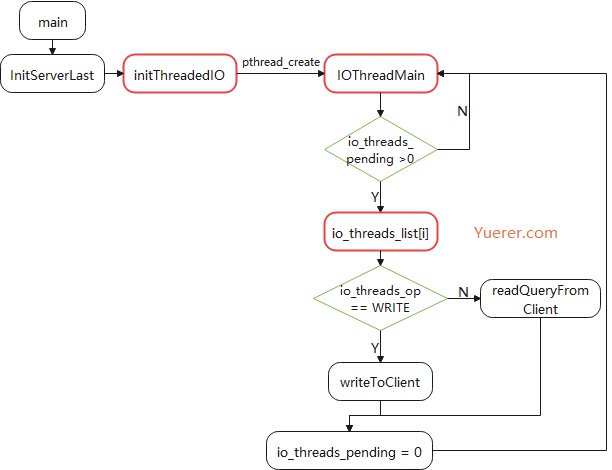
initThreadedIO
根据配置,创建 server.io_threads_num 个子线程,如果只是 一个,则选择直接返回,将 网络I/O的处理放到主线程(相当于使用单线程I/O)。
通过为每个线程创建一个 mutex 来达到 临时开启暂停子线程的功能,之所以需要这样,主要是 子线程都是一个死循环,采用 自旋锁 的形式去获取任务链表,如果一直没有任务,CPU占用也会达到 100%。
1 | /* Initialize the data structures needed for threaded I/O. */ |
IOThreadMain
通过 atomic 实现自旋锁的形式,去获取任务列表,再根据写任务或读任务去执行。其中在一开始的时候通过 lock(mutex) 的形式,给主线程暂停子线程的机会。
1 |
|
Threaded I/O 读写流程
beforeSleep会先遍历所有待读的客户端,采用Round-Robin将其分配到各个线程。- 通过原子操作设置任务数量,交给
I/O线程操作,自旋等到操作完成,再回到主线程执行命令,并加入到clients_pending_write。 - 遍历所有待写的客户端,再次用相同的策略分配到各个线程。
- 通过原子操作设置任务数量,再次交给
I/O线程操作,自旋等待完成。 - 如果还没写完,则设置
Write Handler到epoll,之后未完成的写任务交给主线程去写。
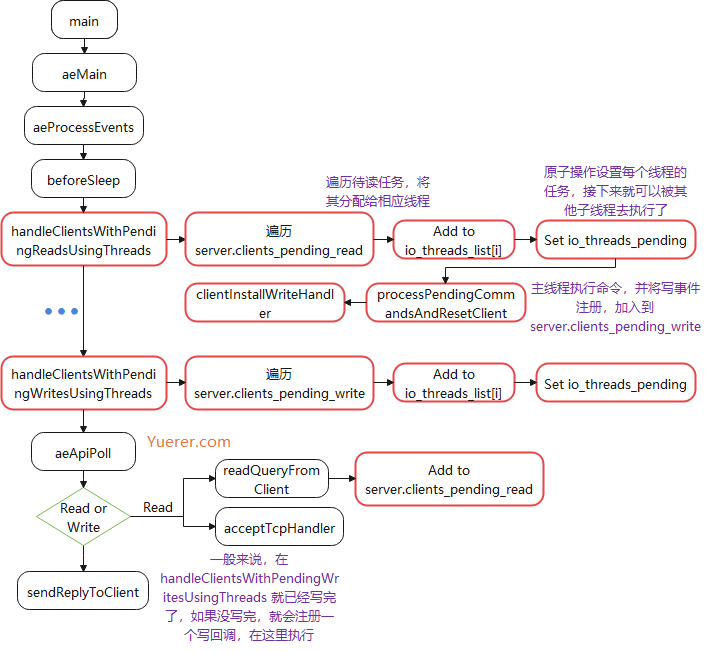
handleClientsWithPendingReadsUsingThreads
读操作,先检查 I/O 线程 是否关闭,从 clients_pending_read 中取出并进行分配到子线程, 访问 io_threads_list 不需要加锁, io_threads_list[i] 只会有主线程和 i子线程访问,而主线程与子线程之间又通过一个原子变量进行同步,之间通过自旋的形式解决了数据竞争的问题,在等待任务完成的同时,主线程也承担一部分的读操作。最后加入到 clients_pending_write 链表。
1 | int handleClientsWithPendingReadsUsingThreads(void) { |
handleClientsWithPendingWritesUsingThreads
写操作,检查一下 I/O线程 是否开启,当任务量少的时候,会通过 lock(mutex) 临时阻塞子线程,因为子线程是一个死循环,就算没有任务也会占满 CPU 。如果没有写完,则会设置写回调,注册到 epoll 中,下次由主线程去写。
1 | int stopThreadedIOIfNeeded(void) { |
可以看出, Redis 的多线程模型并不是那么优雅,主线程完全没必要去等待所有线程的读或写操作,同时 I/O线程 又很暴力,直接一个死循环,吃光CPU,实现起来不够好,不过这也确实解决了单线程下 Redis 因为 read , write 系统调用导致的性能开销(用户缓冲区和内核缓冲区拷贝所带来的)。
在网络中,见到不少人批判 Redis 使用自旋锁是一种开倒车的行为,但我不这么认为,使用 mutex 或者 spinlock 要根据实际情况来,当锁的粒度非常小的时候, spinlock 能够省去不必要的上下文切换的开销。
BIO (三个多线程)
BIO 是 Redis 的后台线程,主要接收以下三种任务,每个任务都会开一个单独的线程。
1 | /* Background job opcodes */ |
- 关闭文件描述符。
- AOF 同步内核缓冲区的数据到文件(fsync)。
- 惰性释放,将部分内存的释放放到另一个线程。
bioInit
初始化三个后台线程的互斥量和条件变量。
1 | static pthread_t bio_threads[BIO_NUM_OPS]; |
bioProcessBackgroundJobs
设置线程名字,阻塞 SIGALRM 信号,然后不断获取任务,根据任务类型进行操作。
1 | struct bio_job { |
关闭文件描述符
关闭文件描述符,有可能会删除掉文件,引起阻塞。因为 Redis 实现的时候会通过 rename 覆盖掉原有文件,将文件描述符的关闭交给 bio 子线程避免阻塞。
客户端交互 (惰性删除)
客户端操作,无非就是对数据结构进行增删改查,大部分的操作都是 O(1),需要注意的是对集合的查询和聚合操作,同时删除一个 BigKey 也会带来性能开销,即使 Redis 用的 jemalloc 已经性能够好了。因此 Redis 选择开子线程的方式,去另一个线程释放内存。
这里有几个条件必须满足。
- 该对象没有其他人共享了。
- 这个对象之后一定访问不到。(hash表中为 value 的情况)
这样做也就不需要加锁了。(Lua 好适合这种情况)
1 | void freeObjAsync(robj *key, robj *obj) { |
因此删除东西最好用 unlink ,当其为 BigKey 时,就会放入 bio 进行释放。同理 flushdb 也可以异步清除。
AOF 日志
每当执行一条命令后,若开启了 AOF日志 则将其记录到 AOF 缓冲区 (写后日志)。
1 | propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags); |
propagate
AOF日志若开启,则调用 feedAppendOnlyFile 将其写入到 server.aof_buf 中。
1 | void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc, |
feedAppendOnlyFile
先检查目前所用的 db, Redis 默认有 REDIS_DEFAULT_DBNUM 16个db。后将有相对时间过期的指令转换为绝对时间。如果有 AOF 子进程在重写日志,则还会将其写入server.aof_rewrite_buf_blocks 链表中,同时通过管道传输到子进程。就算子进程宕机了,主进程的 AOF日志 也还是完整的。
1 | void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) { |
flushAppendOnlyFile
AOF日志同步到硬盘的策略有三种,第一种不同步,由内核自己决定Flush时机,另一种每次都同步,但是 fsync 是会阻塞的,因此还有第三种每秒同步,通过 BIO 子线程,每秒去同步 fsync 一次,其实说是 fsync 也不准确,在 Linux 下用的是 fdatasync 省去了写文件的元数据开销。
1 | void bioCreateFsyncJob(int fd) { |
AOF日志重写 (多进程)
前面提到的 AOF追加日志 是利用了子线程去执行 fsync ,而这里则是用子进程去重写 AOF日志。重写日志主要是根据数据库现状重新创建一份新的 AOF日志,如果在主线程上操作,会导致很长时间不能处理客户端的请求。
AOF日志重写要么是由客户端发起 BGREWRITEAOF,要么是 serverCron 周期性判断是否触发了 AOF重写 。
当前没有其他子进程做事情,比如说 RDB快照,AOF重写,或者 loaded module。
同时默认要求大于 64*1024*1024 并且对比上一次重写后的文件大小是否增长了 100% 。
1 | /* Trigger an AOF rewrite if needed. */ |
rewriteAppendOnlyFileBackground
fork 一个子进程,同时父进程在有子进程的时候, dict 不扩容,这主要是因为 fork 采用的 copy on write ,尽量不去改动进程的内存,避免物理页复制引起内存暴涨,同时一定不要开启 huge page ,原因同上。
最后子进程将数据库信息重写,并从父进程的管道中获取新的数据。
1 | int rewriteAppendOnlyFileBackground(void) { |
子进程完成之后,父进程会在 checkChildrenDone 接受它的返回值。
checkChildrenDone
rename AOF日志文件名,将原文件的文件描述符交给 bio 进行 close 避免阻塞。
可以从 ModuleForkDoneHandler 推论 Module 也预留了 fork 接口去多进程完成一些模块的自定义任务。
1 | void checkChildrenDone(void) { |
RDB 快照 (多进程)
当使用 bgsaveCommand 命令时,类似 AOF重写 ,也是通过 fork 子进程去完成,避免加锁或是减少内存拷贝。当然其也支持自动触发。
1 | /* If there is not a background saving/rewrite in progress check if |
多个检查点,查看是否触发存盘。
1 | int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { |
至于 RDB快照 传送,也是采用子进程生成,父进程发送,若采用无盘传输,则子进程直接序列化后通过管道发给父进程,父进程再发给从服务器,下一篇会比较详细讨论,这里就不细说了。
总结
Redis 除了命令执行是单线程,其他的网络和耗时操作尽可能都转化为 多进程或多线程,简化了开发,这一点在游戏服务器上是非常值得借鉴的。
此外, Redis 通过子线程释放内存,这一点我认为可以将其引用到 Lua 的垃圾回收中,缩短 stop the world 的时间,找个时间,写个多线程垃圾回收的版本,看看其效果。LuaJIT-5.3.6(更新时间 2021年07月04日,已实现 Lua 多线程垃圾回收版本)