近期在压测服务器的过程中发现内存随着用户数增加而暴涨,用户数减少内存却没有释放回内核,一开始怀疑是内存泄漏,后面上了工具排查,最终定位到是 glibc 的内存管理并没有将内存释放给OS,为了解决这个问题,对 ptmalloc2 进行了剖析。
本篇中,不谈论 brk 和 mmap 系统调用的使用方法,默认环境为 Linux-x86-64,讨论的 ptmalloc2 的版本为 glibc 2.17 的版本。
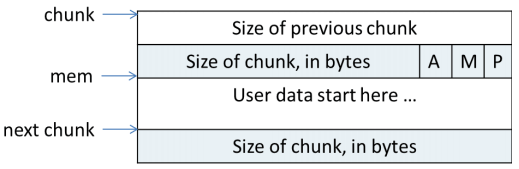
chunk
ptmalloc2 分配给用户的内存都以 chunk 来表示,可以理解为 chunk 为分配释放内存的载体。
1 |
|
chunk 由以上几部分组成, INTERNAL_SIZE_T 为 size_t 为了屏蔽平台之间的差异,这里只谈论64位平台,为8字节。
prev_size代表着上一个 chunk 的大小,是否有效取决于size的属性位P。size代表当前 chunk 的大小和属性,其中低3位为属性位[A|M|P]。- 当这个 chunk 为空闲时,则会使用
fd, bk将其加入链表中管理。 - 同上,
fd_nextsize bk_nextsize只用在large bin中,表示 上/下一个大小的指针,加快链表遍历。
从上可以得出以下结论:
- 当前一个 chunk 非空闲时,
prev_size无意义,可以被前一个 chunk 所利用。 size的低3位为属性位,说明size一定是 8 的倍数,A为是否为非主分配区,1是0否,M为是否从mmap中获取,P为前一个 chunk 是否被使用。- 分配区分两种,主分配区与非主分配区们。
- 当 chunk 非空闲时,
fd bk,fd_nextsize bk_nextsize都无意义,因此返回给用户的可用内存应为size之后。
1 | /* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */ |
mem 为用户真正可用的内存起始地址,可以看出 最小的 chunk 应该至少 4*8 = 32字节,因为 fd_nextsize 和 bk_nextsize 只有在 large chunk 才用的上。
request2size 将用户申请的内存大小转化为 需要分配的 chunk 大小,用户请求大小 (req + prev_size + size) = req + 16B,但是由于内存复用的关系,可以从下一个 chunk 中借用 prev_size 的空间(反正对于下一个 chunk 来说,前一个 chunk 已经被使用了,知道前一个 chunk 的大小也没有意义),因此应为 req + prev_size + size - prev_size(next chunk) = req + 8B,同时 req + 8B 不应小于 MINSIZE 所以二者取最大,为 max(req + 8B, 32B)。
bin
bin 可以理解桶,存放着 chunk ,在 ptmalloc 的世界中存在四种 bin。
- fast bins
- unsorted bin
- small bins
- large bins
fast bins 是小内存块的缓存,当小内存块被回收时,会先放入 fast bins,当下次分配小内存时,就会优先从 fast bins 中找,节约时间。
unsorted bin 只有一个,回收的 chunk 若大于 fast bins 的阈值即 global_max_fast,则放入 unsorted bin 。
small bins 顾名思义,就是 ptmalloc 觉得小的 chunk,就放进去,呈等差数列的形式递增,每个 bin 的 chunk 均为同一大小,通过 fd, bk 链接 chunk 链表。
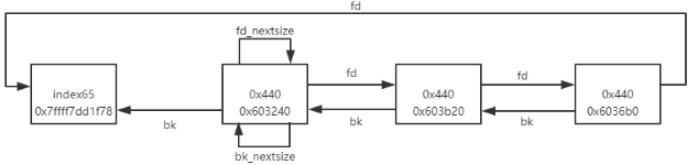
large bins 同上,不过每个 bin 中的 chunk 有大小排序,大的在前,小的在后,通过 fd_nextsize, bk_nextsize 快速找到上/下 一个大小节点。
1 |
bins 共有 small bins 有 62 个, large bins 有 63个, unsorted bin 为 1个,总共为 62+63+1 = 126 个,其中 bin[0] 和 bin[127] 不用,因此 bins 总数为 128 个。要注意 fast bins 并不放入同一数组。
fast bins
fast bins 小内存块的缓存,大小小于 DEFAULT_MXFAST 的 chunk 分配与回收都会在 fast bins 中先查找,在64位上为 128字节,这个参数可以通过 mallopt 函数进行修改,最大值为 160B。一共有 9 个,bin[0] 和 bin[1] 没有用上,剩余 7 个 为 small bins 的小 7 个。
1 |
|
FASTBIN_CONSOLIDATION_THRESHOLD 表示当回收的 chunk 与相邻的 chunk 合并后大于该值 64k,则合并 fast bins 中所有的 chunk 放回到 unsorted bin
unsorted bin
unsorted bin 只有一个, fast bins 合并后的 chunk 会先放到这里,从名字可以看出这里面的 chunk 没有排序。如果从这里面分配不到合适的 chunk 就会将其放到正确的 small bins 或者 large bins 中。
1 |
small bins
small bins 在64位平台上,共有62个bin,最小的 chunk 为 32字节,等差数列的公差为 16B (SMALLBIN_WIDTH),最大为 1008B 。
1 |
将数值带进 smallbin_index 会发现最小的 chunk 是在 bin[2] 上,这是因为为了编程的方便, small bins 从2开始,可以形成 chunk size = 2 * size_t * index 的等差数列,bin[1] 则用来存 unsorted bin 而 bin[0] 为空。
每个 bin 中的 chunk 大小相同,通过双向链表链接起来。
large bins
large bins 则接在 small bins 之后,MIN_LARGE_SIZE 可以看到最小的 large chunk 为 1024B 。共有63个。
1 |
large bins 中的每个 bin 里的 chunk 大小为一个区间,从大到小排序,通过双向链表链接,同时为了加快遍历的过程,通过 fd_nextsize, bk_nextsize 将前后不同大小的对象链接起来。
1 | typedef struct malloc_chunk* mbinptr; |
一些辅助宏,可能会好奇为什么有那么多个 对 malloc_chunk* 的 typedef struct,其实就是 ptmalloc 把内存从不同的角度看待的意思,类似 C++ 的 union 。
malloc_par
malloc_par 可以理解为一个全局的参数。
1 | struct malloc_par { |
其中较为重要的参数有:
- trim_threshold,mmap 的收缩阈值 默认128KB
- mmap_threshold,mmap 分配阈值 默认128KB
- n_mmaps_max,mmap 分配内存块的最大数
- no_dyn_threshold,是否关闭动态调整分配阈值 默认开启
以上任一项的修改,都会关闭 动态调整分配阈值,之所以有这个机制,是为了减少 mmap 的次数,因为 mmap 的效率远远低于 brk。更多细节建议阅读 mallopt(3) — Linux manual page。
但是使用 mmap 分配的内存有一个好处,当释放的时候可以直接还回给内核,而且当虚拟内存空间有洞时,只能用 mmap 进行分配,在本次服务器压测的过程中,通过修改以下配置达到释放内存的目的,但是强烈不建议使用, mmap 分配的内存以页为单位,哪怕你申请 1B,都会变成向内核申请一块页大小的内存块,仅适合用于排查内存不释放究竟位于 ptmalloc2 的哪个地方。
1 |
|
malloc_state
前面提到过,申请出来的 chunk 可能来自三个地方。
- mmap 直接申请
- 主分配区分配
- 非主分配区分配
malloc_state 就是用来管理分配区的。非主分配区的出现主要是为了缓解多线程的场景下,减少锁争用的情况,一般情况是一个线程对应一个非主分配区,尽管是这样还是会进行加锁,因此性能不佳,分配区达到CPU核心数时,则会停止创建非主分配区,转而进行复用,复用也很简单,轮询判断是否可以加锁。
1 |
|
- mutex,为了支持多线程
- flags,bit0 表示是否有 fast bin chunk,bit1 表示是否能返回连续的虚拟地址空间,显然只有主分配区才能做到,因为在未达到 mmap阈值 时,只有主分配区是用
brk进行分配,而非主分配区都是采用mmap。但也有一种情况,主分配区用mmap,静态链接glibc的时候,就会禁用brk,我想是担心出现洞。 - fastbinY,就是存储 fast bins 的数组,NFASTBINS 为 10。
- top,top chunk 前面一系列的 bin 分配不到内存,就从 top chunk 里拿,释放回内核也是从 top chunk 开始释放,即从高地址开始释放 类似于 stack。
- last_remainder,分配区若上次分配 small chunk 且还有剩余,则存入这个指针。
- bins,即 unsorted bin + small bins + large bins = 1 + 62 + 63 = 125,bin[0] 和 bin[127] 没有用,但是 bins 的大小为 254,这主要是为了节约内存,可以理解为它只是用数组来申请内存,然后将其转化为双向链表的结构体。
- binmap,标识 bit 指向的 bin 是否有空闲 chunk。
- next,链接分配区。
- system_mem,当前分配区已分配内存大小,可通过
malloc_stats(3)进行查看。
内存分配
本节先通过文字描述一遍内存分配流程,再进行代码分析。malloc glibc 内部名字为 __libc_malloc
- ptmalloc 是否没有初始化或者有钩子函数,调用指定函数(如果使用 其他malloc,就在此处返回了)。
- 查找合适的分配区,加锁,,调用
_int_malloc在分配区中分配内存,如果分配失败,则解锁分配区并换一个分配区,如果分配区的数量少于CPU核心数,则默认是新建一个非主分配区,并调用mmap分配一块大内存并设置好 top chunk。 - 进入
_int_malloc逻辑。 - chunk_size ≤
128B,是则在 fast bins 中查找并返回,否则下一步。 - 若 chunk_size <
1008B则在 small bins 进行分配,优先用last_remainder,从尾节点先分配,头结点还回,使每一个chunk都有机会被用上,成功则返回,否则下一步。 - 若到这一步要么是 还没找到合适的内存,或者是 chunk_size 是一个 大的请求,则先遍历 fast bins,将相邻的 chunk 进行合并,放入到 unsorted bin 中,从 unstorted bin 中进行查找,一边找一边将其放入正确的 bins 中,同时在 binmap中进行标记。如果找到则返回给用户,若
unsorted bin只有一个 chunk,且 该 chunk 为 last remainder chunk,且我们需要的是一个 small bin chunk,则将其切分,剩余部分依然不动,此步骤最多尝试MAX_ITERS(10000)次,防止因为 unsored bin 的 chunk 过多而影响分配效率。 - 最后还是找不到,那就在
large bins中按照最佳匹配的原则,从更大的 bins 中进行查找,查找方式是通过遍历binmap,找一个合适的chunk,并将其切分,成功则返回,否则下一步。 - 只好从
top chunk进行切分了(回收的时候也是从top chunk进行切分,埋下了长周期的内存无法回收导致内存暴涨的伏笔),不成功下一步。 - 又开始打
fast bins的注意了,主要是fast bins回收的时候没有加锁,而是采用lock-free方式(Compareand-Swap)回收,因此有可能里面已经有 chunk 了,这时候又开始合并,放入 unsorted bin,但是却是从 small bins 或从 large bins 中再去查找,这主要是因为,在第 5,6 步的时候,如果在 small bins 中找不到合适的 chunk,就合并 fast bins 到 unsorted bin,然后放回到指定的 small bins 和 large bins 中,但是并没有再去扫描一下相应的 bins,这里相当于再补上一刀。 - 山穷水尽了,调用
sysmalloc向内核申请内存了,先看看是否超过 mmap 分配的阈值,若没超过,主分配区采用brk扩充 top chunk 大小(若静态链接brk会被禁用,此时采用mmap),非主分配区则默认用mmap进行扩充,超过就更不用讲了,直接mmap分配给用户,释放也是直接释放即可。 - 分配成功。解锁分配区并返回。
1 |
|
可以看出 分配区是绑定在线程的,但并不代表每个线程独占一个分配区,因此都要加锁,导致性能无论在单线程还是多线程上都不佳。同时 分配区的数量取决于 CPU核心数,若获取不到则默认为 8。
1 | void* |
_int_malloc
_int_malloc 可以说是 ptmalloc2 中最重要的函数之一,它可以说是 ptmalloc2 内存分配策略的实现。
1 | static void* |
以上为内存分配的第 4 步 fast bins,这里采用了 CAS 操作,换句话说 回收 fast bins 不需要加锁。
1 | if (in_smallbin_range(nb)) { |
内存分配第五步 small bins 至此结束。
1 | else { |
第六步至此结束,到这要么是 small bins 不满足 或者 本身请求就是一个 大请求,因此先整合 fast bins 的 chunk,将其放入 unsorted bin 中,一边又从 unsorted bin 中查找,顺便放入正确的 bins 中,如果碰巧就找到了 那就返回就完事了,同时还会设置 binmap,方便之后搜索。
1 | /* |
第七步主要是从更大的 bins 中进行查找,然后进行切分,如果切分后剩余的内存太小则一起送给用户,还有很多的话,则将其插入到 unsorted bin ,分配的是小内存则还会将其剩余部分保存到 last_remainder 供下次优先分配。
1 | use_top: |
第八步,从 top chunk 中进行切分,回收也是从 top chunk 从高往低释放回给内核,因此如果后分配的没有释放,会导致先分配的已释放都没办法还回给内核。
1 | /* When we are using atomic ops to free fast chunks we can get |
第九步,fast bins,因为 fast bins 的回收是不需要锁的,有可能回收了。
1 | /* |
第十步,一滴也没有了,通过 sysmalloc 从内核申请内存。
sysmalloc
主分配区用 brk 申请一块内存进行内存分配,若是静态链接 glibc 则只能用 mmap 防止有洞。非主分配区则只能用 mmap 。还会先看看所需内存是否大于 mmap 的阈值,大过就直接采用 mmap 返回。但是 mmap 的效率不高,在内核中属于串行运作,因此 ptmalloc2 会动态调整这个阈值(默认为 128KB,最大可达 32MB)换句话说你要想百分百用 mmap 申请内存,那请你申请大于 32MB 的内存。
1 | static void* sysmalloc(INTERNAL_SIZE_T nb, mstate av) |
内存释放
依然是文字先总结一遍流程。
- 先检查是否有钩子函数,有则调用并返回。
- 如果是
mmap分配的 chunk,则用munmap将其释放,如果释放的chunk大小大于mmap分配的阈值,且未关闭动态调整阈值开关,则调整一下mmap的阈值为当前chunk大小。 - 调用
_int_free释放内存。 - 若
chunk_size<128B,且 chunk 不与top chunk相邻则放入fast bins中,这里不会加锁,而是用的CAS,返回。 - 加锁分配区,前一个 chunk 若空闲,则合并。
- 后一个 chunk 若为
top chunk,则将其合并到top chunk中,若不是也合并,将其放到unosrted bin。 - 如果合并的
chunk大于64KB,则开始整合fast bins到unsorted bin,若top chunk的大小 大过 收缩阈值了,默认为128K,则收缩堆,也就是还给内核。 - 也就是说 释放内存回内核 需要两个条件,
chunk_size>64KB,且top chunk大于收缩阈值,则释放。
__libc_free
1 | void |
_int_free
只放出最重要的一段,收缩堆的条件。
1 | if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { |
其他细节
由于 ptmalloc 用了 mutex ,如果一个多线程的进程执行 fork 会将执行 fork 的线程进行拷贝,其他线程会突然消失,这个时候子进程的 mutex 处于不安全的状态,只能直接重新初始化。关于这一点可以查看 ptmalloc_unlock_all2 这个函数。
1 | thread_atfork(ptmalloc_lock_all, ptmalloc_unlock_all, ptmalloc_unlock_all2); |
扩展堆和收缩堆还有释放堆的几个操作补充一下。
1 | /* Grow a heap. size is automatically rounded up to a |
结语
通过了解 ptmalloc2 分配释放内存的策略,可以知道,它比较适合短生命周期的内存分配,若是长生命周期的内存,则会不断抬高 top chunk ,导致无法将内存释放回内核,引起内存暴涨。而游戏服务器中,玩家的内存数据很有可能要等一个小时以上才释放,生命周期比较长,因此最好的做法还是自己写一个基于 mmap 的内存池(打脸了 在Lua GC垃圾回收优化方案中我还提到,认为内存池没有必要),之所以特意强调是基于 mmap 主要是 brk 它类似于栈,会将堆顶抬高,如果堆顶内存没释放,会导致堆顶以下的内存都不能还回内核,又会导致内存暴涨。